




【疫学専門家監修】逆確率重み付け(Inverse Probability Weighting)を徹底解説 - 交絡調整の基本をわかりやすく図解 - ゼロから学ぶ因果推論 vol.6
2025.01.18
シリーズ紹介|ゼロから学ぶ因果推論
「医学研究は難しい」、きっと多くの方がそう感じているでしょう。
因果推論は、そんな複雑怪奇な医学研究にスッと一本の軸を通してくれる、まさに医学研究の原理原則とも言える学問です。
因果推論を学ぶことで、複雑に散らばっていた知識の断片が見事なまでに因果推論という幹へと体系立てられていきます。そしてきっと「論文、読めるようになってきたかも」、そんな気持ちになれるはず。
「ゼロから学ぶ因果推論」シリーズは、疫学専門家の監修のもとで「はじめて学ぶ人の気持ち」に寄り添い、具体例や図解を使用して「日本でいちばんわかりやすい因果推論の解説」を目指しました。あなたの歩幅で一歩ずつ。ゼロからの学びをはじめしょう。
はじめに
この記事ではIPW(Inverse Probability Weighting:逆確率重み付け)について解説します。
一見して難解に思えますが、やっていることは非常にシンプルです。
様々な研究で頻繁に使われているとても重要な手法であるIPWについて、ゆっくりと紐解いていきましょう。
mMEDICI Library | ひらけ、叡智の扉
叡智の扉を、全ての人が開けるように——。
学びは、限られた豊かな人々だけの特権ではありません。
経済的困難に直面する人、地方で学習資源に恵まれない人、家事や育児・仕事に追われる人。
mMEDICI Libraryではそんな人々にこそ、最高の学びを届けるため、研究・キャリア・学習・受験のあらゆるテーマでパブリックヘルスの叡智を集めました。
隙間時間にスマホひとつで、誰もが「一流の知」に触れることを叶えていきます。
「ここを開けば、誰しもが悩みを解決できる」、そんなメディアを目指します。
この記事のまとめ
この記事を読むと分かること
IPWの理論を視覚的に理解できる
簡単なデータに対して、IPWを実践できる
IPWの理解を『傾向スコア』のイメージに繋げる
この記事は誰に向けて書かれているか
因果推論について初めて学ぶ方
統計学や数式が苦手な方
IPWについて理解を深めたい方
因果推論シリーズ
vol.1:因果推論の出発点 - 因果と関連の違いとは? -
vol.2:因果効果の基本を徹底解説 - Individual Causal Effect(個人因果効果)とAverage Causal Effect(平均因果効果)の違いとは? -
vol.3:初心者のためのTarget Trial Emulation(TTE)
- Part 1 ; ETAFOCAフレームワークについて
- Part 2 ; 三つの時点で考えるバイアスとその対処法
- Part 3 ; 論文の実例で理解を深めるTTEvol.4:Exchangeability(交換可能性)を徹底解説 - Randomization(ランダム化)が実現する因果推論の必須条件 -
vol.5:Standardization(標準化)を徹底解説 - 交絡調整の基本をわかりやすく図解 -
vol.6:Inverse Probability Weighting(逆確率重み付け)を徹底解説 - 交絡調整の基本をわかりやすく図解 -
vol.7:Consistency(一致性)を徹底解説 - 観測データと反事実アウトカムを一致させよ -
vol.8:Positivity(正値性)を徹底解説 - 因果推論の落とし穴を回避せよ -
vol.9:Immortal time biasを徹底解説 - 臨床研究に潜む「不死の時間」の罠 -
vol.10:効果修飾を徹底解説 - 私たちは「どの集団における」効果を見ているのか? -
vol.11:交互作用を徹底解説 - 複数の介入による相乗効果 -
vol.12:DAGを徹底解説
vol.13:交絡を徹底解説 - 結果を歪める、因果推論の最重要課題 -
vol.14:選択バイアスを徹底解説 - 消えた患者が結果を歪める?-
執筆者の紹介
氏名:岡部 陽介
所属:理学療法士養成校 専任教員
経歴:理学療法士として5年間の臨床経験を経て、現在は理学療法士養成校で教員として勤務。ヘルスコミュニケーション、医療者と患者の共有意思決定(SDM:Shared Decision making)に関心を持つ。令和7年4月より国際医療福祉大学大学院 公衆衛生学専攻へ進学予定。
編集者
氏名:菊池祐介
所属:mMEDICI株式会社
専門性:作業療法学修士。首都大学東京(現東京都立大学)・東京都立大学大学院を卒業後、病院勤務を経て専門学校・私立大学にて作業療法教育、地域共生社会の醸成に向けたリハビリテーション専門職の支援に関する研究に従事。現在は心身の健康とその人らしさの実現に向け、保険内外でのクライアント支援を展開している。作業療法の社会的意義向上を信念に、mMEDICI株式会社に参画。
監修者
氏名:廣瀬直紀
所属:mMEDICI株式会社
専門性:保健学博士・公衆衛生学修士。東京大学・東京大学大学院を卒業後、外資系製薬企業の日本・グローバルにおいて疫学専門家として薬剤疫学・リアルワールドデータ研究に従事。その後、全ての人がアクセス可能な一流の知のプラットフォームを作り、「知に繁栄を、辺野に豊穣を」実現すべく、mMEDICI株式会社を創業。
IPWとは
さて、今回のテーマはIPWです。
「代表的な交絡調整の手法であるIPWは、Inverse Probability Weightingの略で、日本語では逆確率重み付けといいます」
いかにも難しそうですね。
これを見た方の多くは「きっと意味不明な数式が出てくるに違いない」と身の危険を感じていることでしょう。
その名を目にした者を一瞬で不安に陥れ、学ぶ意欲を挫く。
そんな恐ろしい魔力を放つ『IPW』ですが…
ご安心ください。
実はIPW、やっていることは非常にシンプルです。
IPWの考え方を理解するために必要なのは、
「足し算」「引き算」「掛け算」「割り算」たったそれだけで、とても簡単です。
そして、『逆確率』なるものを駆使して巧みに因果推論を実現しようとするロジックはとても面白く、きっと皆さんもIPWに「よくこんな手法思いつくなぁ」と感動するはずです。
さて、さっそく次の章からIPWの解説を進めていきますが、その前にひとつ大切なことを。
因果推論は本当に魅力的な学問ですが、その学びを進めるためには難しい概念や理論を避けては通れません。
初学者にとっては、一歩進んでは立ち止まり、時には後戻りして、また立ち止まる…という繰り返しで、「因果推論を学び、実践できる未来」までは途方もない道のりに思えますよね。
そんな初学者に寄り添い、mMEDICI Libraryでは専門家の監修のもとで因果推論の理論を一つひとつ順を追って丁寧に解説をしています。
もし、この記事の途中で行き詰まったときは、過去の記事をじっくり読み直していただけば、きっと手がかりが掴めるはずです。
それでは、皆さんのペースで少しずつ前進していきましょう!
IPWのイメージ
これまでに、因果推論において正しく因果効果を推定するためには「交絡因子をどうやって調整し、いかにExchangeabilityを実現するか」が大切と学んできました。
前回の記事では交絡調整の手法である標準化について学びました。今回解説するIPWも標準化と同じく交絡調整の代表的な手法のひとつです。
とりあえず、IPWでやっていることはこんなイメージです。

層別化で整え、逆確率でキメる。
という具合です。(逆確率によって「擬似集団(Pseudo population)」を生成することで因果効果を推定するというのがIPWのミソとなります。)
「いきなり逆確率って何よ?」「擬似集団とは?」という疑問については、後ほどしっかりとご説明しますのでご安心を。
とりあえずIPWは
「実際に治療を受けた人たち・受けなかった人たちの結果(Association)」
を「もし全員が治療あり・なしだった時の結果(Causation)」
に変換できる「めっちゃ便利な統計手法」くらいの理解でよいかと思います。
この時点で、もうすでにIPWのイメージは8割が仕上がっています。
この記事を最後まで読んでいただき、残りの2割をしっかりと咀嚼していただければ、「IPWわかったかも」というレベルまで理解が深まるはずです。
このまま具体的なIPWの理論に進む前に、まず前提として因果推論で目指していることと交絡調整の考え方を理解することが大切ですので、前回までに学んだ内容をサクッと復習してIPWへと繋げていきましょう。
因果効果の目的とExchangeabilityとは
因果推論の目的は、
現実で得ることができる結果:
「実際に治療を受けた人たち」 と 「実際に治療を受けなかった人たち」の結果の差(Association)から
現実では得られない結果:
「もし全員が治療を受けた時」と「もし全員が治療を受けなかった時」の結果の差(Causation)を推論することでした。

そのためには「治療あり群」と「治療なし群」とでExchangeabilityが保証されていることが絶対条件で、Randomizationによって治療をランダムに割り付けることでExchangeabilityの成立が期待されるのでしたね。

しかし、たとえRandomizationを行っても偶然に交絡因子の分布が「治療あり群」と「治療なし群」とで偏ってしまい、Exchangeabilityが保証できない可能性がありました。
そこで、この問題に対して「層別化」によって対処したわけです。
(全体ではなく交絡因子の有無による各層の中でRandomizationすることで、各層内でExchangeabilityが成り立つ、すなわちConditional Exchangeabilityが成り立つというわけです。)

ただし、層別化ではそれぞれの層である「交絡因子ありの人たち」・「交絡因子なしの人たち」ごとの結果しか知ることができないのでした
そこで、前回の記事では標準化によって、
層別化で求められた結果から集団全体における治療の効果を推定したのでした。


ここまで、かなり端折って説明をしています。「これどういう意味だっけ?」と思った方は、前回の記事でじっくり丁寧に解説していますので読み返していただけたらと思います。
<標準化:Standardization>
IPWは、標準化と同様に層別化で求められた結果から「仮に全員が治療を受けた時」・「全員が治療を受けなかった時」の結果を推定します。
「どういうこと?」と思われたことでしょうが、さっそく次の章でIPWの詳細に踏み込んでいきましょう。
IPWの理解へ 〜逆確率とは〜
さて、IPWでは層別化で求められた結果から「全員が治療あり・なしだった時」の結果を推定します。
ここで登場するのが「逆確率」です。
逆確率について簡単に説明しましょう。
例えば、2%の確率で当たる福引があるとします。
この場合の逆確率はこのようになります。

2%の逆確率は50、とっても簡単ですね。
この数字をどう使うのかといいますと、例えば、この福引の当選者が2名だったとしましょう。
当選者の人数(2名)に逆確率50をかけてあげると、100名という数字が求められます。

つまり逆確率を使うことで、
「当選者の人数(2名)」が分かれば「応募者全体の人数(100名)」を求めることができます。
ここでピンときた方、ご明察です。
因果推論おいても、逆確率を上手く使うと「治療を受けた人たちの人数」から「集団全体の人数」を求めることができそうですね。
これがまさに、IPW(逆確率重み付け)が目指しているところです。
さて、次の章でこの逆確率を駆使してIPWによる因果効果の推定を試みてみましょう。
いざ、IPWを実践
IPWを実践していくために、以下のような対象集団を使っていきます。

この研究の目的は発熱患者20名に対する治療A(解熱剤)による重症化リスクを検証することです。
全体の20名のうち12名は、発熱の重症化を高め得る基礎疾患(例えば呼吸器疾患など)、いわゆる交絡因子を有しています。
まずは交絡因子(L=1 と L=0)の有無で全体を層別化し、各層の中でRandomizationにより治療Aをランダムに割り付けます。

ここでは治療AをL=1のグループでは75%の確率で割り付け、L=0のグループでは50%の確率で割り付けています。 (この確率を「治療の割り付け確率」と呼びます。)
ここで、L=1 と L=0 それぞれの層における治療ありの人たちに注目してみます。
治療を受けた人の数を数えると、
L=1:9名、L=0:4名、合計13名ですね。
さて、治療の結果である発熱の重症化の有無がイラストの様になったとしましょう。

そして、逆確率の出番です。
L=1 と L=0 それぞれの層の結果に対し、逆確率で重み付けすると何が起こるでしょうか?

ポイント
ここで使われているのは「治療の割り付け確率」の逆確率です。
L=1 ・・・75% 1/0.75 = 1.33
L=0・・・50% 1/0.5 = 2
このように、それぞれに逆確率をかける(逆確率によって重み付ける)ことによって、L=1の集団では治療ありの人数が12名となり、L=0の集団では治療ありの人数が8名となっています。
勘の良い方は気づいたかもしれませんが、12名というのはもともとのL=1の集団の人数であり、8名というのはもともとのL=0の集団の人数です。
つまり、L=1・L=0のそれぞれの層内における治療ありの人数に対して逆確率で重み付けすることで、「仮にL=1の全員が治療を受けた場合」と「仮にL=0の全員が治療を受けた場合」の集団を擬似的に生成することができたことになります。
ちなみに、こうして逆確率によって生成された集団のことを、擬似集団(Pseudo population)と呼びます。
(シュード・ポピュレーションと発音するそうです。私は最初、ぷしぇうど...?と困惑しました。)
そしてL=1 と L=0 の疑似集団を足し合わせると、現実世界では観測できなかった「もし集団全員が治療を受けた場合」の結果を再現した疑似集団をつくることができます。

実際に治療を受けた13名(L=1:9名 + L=0:4名)を逆確率で重み付けすることで、全体の人数である20名の集団が形成され、そのうちの10名が重症化したという結果が得られました。
同様に、L=1・L=0それぞれの層内において、治療を受けなかった集団に対しても治療を受けない確率の逆確率で重み付けしてやれば、「もし全体集団が治療を受けなかった場合」の結果を再現した擬似集団を作ることが出来ます。
IPWによる因果効果を計算してみよう
前章の内容を数式で整理していきましょう。
測定したい因果効果は以下の式で表されます。
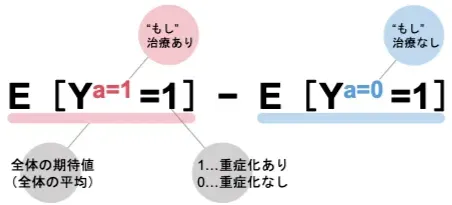
つまり「もし全員が治療を受けた場合」と「もし全員が治療を受けなかった場合」の結果の差分ですね。
「全員が治療を受けた場合」の重症化リスク

全員が治療を受けた場合の集団全体の重症化リスクは
E[Y^{a=1}=1]=0.5 となります。
「全員が治療を受けなかった場合」の重症化リスク

全員が治療を受けなかった場合の集団全体の重症化リスクはE[Y^{a=0}=1=0.5]となります。
これで「仮に全員が治療を受けた時の結果」と「仮に全員が治療を受けなかった時の結果」が算出されましたので、あとはこの値を使って平均因果効果を求めてみましょう
E[Y^{a=1}=1] - E[Y^{a=0}=0] = 0.5 - 0.5 = 0
つまり、今回の例では発熱者に対する治療A(風邪薬)は、治療を受けた場合・受けなかった場合ともに重症化リスクが50%で等しいため「治療Aは重症化リスクに影響しない」と言うことができそうです。
IPWの注意点
逆確率によって疑似集団を生成できる点はとても便利ですが、例えば「治療の割り付け確率が1%」のような場合には逆確率は100となり(1/00.1 = 100)、とても極端な重み付けをすることになります。
実際に治療を受けた人がたった数名だとしても、その結果を100倍にしてしまうことになると、とても偏った性質を持つ疑似集団を生成してしまうのは想像に難くありません。
この点には気をつける必要がありますね(その対処法となる統計手法もありますが、ここでは詳細過ぎるので述べません)。
IPWのポテンシャル
〜傾向スコア、さわりだけ〜
さて、前の章までIPWの概要から因果効果の計算までを解説してきました。
逆確率によって「もし全員が治療あり・なし」の疑似集団を生成してしまうIPWのロジック、とても興味深いですよね。
「はじめに」でも申し上げたように、IPWは因果推論や様々な医学研究で使用される発展的な分析手法の基礎でもあります。
ここでは少しだけ、IPWに用いられることがある傾向スコアについて解説したいと思います。
傾向スコア(Propensity score)という言葉は、皆さんもどこかで目にしたことがあるのではないでしょうか?
「傾向っていったい、何の傾向?」と誰もが戸惑うところと思います。
ずばり「治療を受ける傾向」のことを表現しています。
前の章の例では治療を受ける傾向は
L=1のグループは75%、L=0のグループは50%でした。

これを傾向スコアの考え方で言い換えると、L=1の集団は、75%という「治療の受けやすさ」、すなわち傾向スコアをもっていると言い換えることができます。
(基礎疾患があり重症化リスクが高いため、治療を割り当てられる確率も高くなる、という解釈です)
臨床において「治療の受けやすさ」は様々な因子によって規定されます。例えば重症度、年齢、性別、治療歴、人種などですね。
傾向スコアの特徴は、これらの複数の因子を傾向スコアという一つの指標に要約することができる点にあります。
前回の記事では、標準化の弱点として、交絡因子が複数ある場合には層別化する数が増え、うまく対処できなくなってしまう問題がありましたね。
具体的に考えてみましょう。
年齢、性別、基礎疾患という3つの背景因子があるとします。
特定の統計モデルを使うことで、これらの背景因子を組み合わせ、「このような背景因子の組み合わせを持つ人は、このくらい治療を受けやすい傾向にある」という傾向スコアを算出することができます。
例えば、年齢:高齢、性別:男、基礎疾患:あり、という3つの背景因子の条件を持つ人が20名いたとして、計算によって傾向スコアが0.75(治療を受ける確率が75%)だったとしましょう。

続いて、実際に治療を受けた人が15名だったとします。
治療ありの人の人数に、傾向スコア0.75の逆確率の値(1/0.75=1.33)をかけ、重み付けしてみましょう。

「実際に治療を受けた、傾向スコアが0.75程度の人たち(15名)」に1.33倍の重みが与えられることで、「もし、同程度の傾向スコアを持つ全員(20人)が治療を受けたら」の疑似集団を生成することができましたね。
それでは、もう少し発展させて考えてみましょう。
例えば、ある治療の効果を検証する研究における対象(60名)が、次のように様々な背景因子の組み合わせをもっていたとしましょう。

それぞれ背景因子の組み合わせによって、次のように傾向スコアが求められたとします。
・高齢 ••• 0.25
・高齢、男性 ••• 0.5
・高齢、男性、基礎疾患あり ••• 0.75 同じ傾向スコアを持つグループごとに、次のように治療を受けた人がいたとしましょう。

傾向スコアのグループによって治療を受けた人数に偏りがありますね。
続いて、傾向スコアのグループごとに、それぞれの傾向スコアの逆確率によって重み付けを行います。

傾向スコアが小さい人たち(0.25)にはより大きな重み(4)が、傾向スコアが大きな人たち(0.75)にはより小さな重み(1.33)が与えられています。
結果として、
「もし傾向スコア0.25の人たち全員が治療を受けたら」
「もし傾向スコア0.50の人たち全員が治療を受けたら」
「もし傾向スコア0.75の人たち全員が治療を受けたら」
という疑似集団が生成されています。
これらの疑似集団を足し合わせることで「もし全員が治療を受けた場合」を再現した疑似集団を生成し、「もし全員が治療を受けた場合の結果」を求めることができるわけです。
同様にして、「治療なしの人たち」においても傾向スコア(厳密にいえば、1-傾向スコアの値)を使ったIPWによって「もし全員が治療を受けなかった場合の結果」を計算することができます。
このようにして、私たちが測定したい治療による平均因果効果、つまり「もし全員が治療を受けた場合の結果」と「もし全員が治療を受けなかった場合の結果」の差分を計算する事ができるのです。
ここまでの説明で、傾向スコアを用いたIPWによって、背景因子が複数ある複雑なデータにおいても「実際に治療ありの人たち・なしの人たちの結果(Association)」から「もし全員が治療あり・なしだった時の結果(Causation)」を推定できることがイメージできたのではないでしょうか?
概念的な説明ではありましたが、大まかにでも分析手法のイメージを持てると、論文を読んだときに一歩踏み込んで理解することができるかもしれませんね。
おわりに
前回の記事では標準化について学び、今回はIPWについて理解を深めました。
どちらも交絡調整の代表的な手法であり、因果推論の基礎をなす理論でもあります。
標準化とIPWの理解を深めることは、より実践的で高次元な理論を学ぶ土台作りになるはずです。
これから先、因果推論の学習を進めるなかで行き詰まった時にはこれらの記事に戻ってきていただき、皆さんが一歩先へ進むためのヒントを見つけていただけたらと思います。
これからも、因果推論の学びを深めていきましょう!
参考文献
Hernán MA, Robins JM (2020). Causal Inference: What If. Boca Raton: Chapman & Hall/CRC .https://www.hsph.harvard.edu/miguel-hernan/wp-content/uploads/sites/1268/2024/04/hernanrobinsWhatIf26apr24.pdf
林 岳彦.はじめての統計学的因果推論.岩波書店,2024.
KRSK.データから因果関係をどう導く?:統計的因果推論の基本、「反事実モデル」をゼロから.URL: https://www.krsk-phs.com/entry/counterfactual_assumptions (2024年11月16日閲覧)
参考図書:『Causal Inference: What If』
Causal Inference: What Ifとはハーバード大学のSPHで教鞭をとるMiguel Hernan氏とJames Robins氏によって執筆された因果推論の金字塔的書籍です。
mJOHNSNOWでは、こちらの書籍を用いて輪読会を行い因果推論をゼロから学んでいます。
因果推論を学ぶならオンラインスクールmJOHNSNOW
この記事を読み、「もっと因果推論を学びたい」と思われた方もいらっしゃるでしょう。
そんな方には弊社が運営するオンラインスクールmJOHNSNOWがお勧めです。
mJOHNSNOWはスペシャリストが運営する臨床研究・パブリックヘルスに特化した日本最大規模の入会審査制オンラインスクールです。運営・フェローの専門は疫学、生物統計学、リアルワールドデータ、臨床、企業など多岐に渡り、東大、京大、ハーバード、ジョンズホプキンス、LSHTMなど世界のトップスクールの卒業生も集まっています。
本日解説した因果推論の講義に加えて、みなさんの専門性を伸ばすためのコンテンツが目白押しです!
・スペシャリスト監修の臨床研究・パブリックヘルスの講義が毎月7つ以上開催
・過去の講義が全てオンデマンド動画化されたレポジトリー
・スクール内のスペシャリストに学術・キャリアの相談ができるチャットコンサル
・フェローが自由に設立して学べるピアグループ(ex. RWDピア)
・24時間利用可能なオンライン自習室「パブリックヘルスを、生き様に」をミッションに、『初心者が、自立して臨床研究・パブリックヘルスの実践者になる』ことを目指して学んでいます。初心者の方も大勢所属しており、次のような手厚いサポートがあるので安心してご参加ください!
・オンデマンド動画があるから納得するまで何回でも、いつでも学び直せる
・チャットコンサルで質問すれば24時間以内にスペシャリストから複数の回答が
・初心者専用の「優しいピアグループ」で助け合い、スペシャリストが”講義の解説”講義を毎月開催因果推論シリーズ
vol.1:因果推論の出発点 - 因果と関連の違いとは? -
vol.2:因果効果の基本を徹底解説 - Individual Causal Effect(個人因果効果)とAverage Causal Effect(平均因果効果)の違いとは? -
vol.3:初心者のためのTarget Trial Emulation(TTE)
- Part 1 ; ETAFOCAフレームワークについて
- Part 2 ; 三つの時点で考えるバイアスとその対処法
- Part 3 ; 論文の実例で理解を深めるTTEvol.4:Exchangeability(交換可能性)を徹底解説 - Randomization(ランダム化)が実現する因果推論の必須条件 -
vol.5:Standardization(標準化)を徹底解説 - 交絡調整の基本をわかりやすく図解 -
vol.6:Inverse Probability Weighting(逆確率重み付け)を徹底解説 - 交絡調整の基本をわかりやすく図解 -
vol.7:Consistency(一致性)を徹底解説 - 観測データと反事実アウトカムを一致させよ -
vol.8:Positivity(正値性)を徹底解説 - 因果推論の落とし穴を回避せよ -
vol.9:Immortal time biasを徹底解説 - 臨床研究に潜む「不死の時間」の罠 -
vol.10:効果修飾を徹底解説 - 私たちは「どの集団における」効果を見ているのか? -
vol.11:交互作用を徹底解説 - 複数の介入による相乗効果 -
vol.12:DAGを徹底解説
vol.13:交絡を徹底解説 - 結果を歪める、因果推論の最重要課題 -
vol.14:選択バイアスを徹底解説 - 消えた患者が結果を歪める?-







©mMEDICI Inc. ALL RIGHTS RESERVED.